Mahindra First Choice Services (MCFS) Business Analysis
Mahindra First Choice Services (MFCS) is a company of Mahindra Group and is India’s leading chain of multi-brand car workshops with over 335+ workshops present in 267+ towns & 24 states. It has serviced over 10,50,000 cars. The company aims to establish countrywide network of over 400 workshops by March 2018. Mahindra would now like to leverage the data that they have and address the key issues they have. Read along to know how you can help them improve their business. The dataset consist of three aspects:
- Customer data: where the details of the customer like the car owned, state and place of residence, order type, etc are present. Data dimension is of 534000 Customer entries
- Invoice data: where information related to customer visits and transactions are recorded, whether a customer as insurance claims, bifurcation of the amount paid, for what type of service did the customer came for, etc…
- Material Inventory: where information related to what kind of service did the customer took and what kind of material was used to service, Labor information and the cost for the service, Plant and plant name where the customer took the service.
Problem Statement-1: Identifying the ownership pattern of cars throughout the country. This also captures the problem wherein information regarding the spending patterns can be identified.
- Mahindra First Choice Services will be benefited in multiple ways. Knowing the ownership pattern targeted marketing campaigns could be carried out. Knowing the spending patterns services could be suited to the particular spending pattern.
Problem Statement-2: Identify the various types of orders.
- This could potentially give information about how Mahindra First Choice needs to be prepared to tackle various seasonal cases.
Problem Statement-3: Revenue Analysis.
- This would help determine which streams of revenue are beneficial and improve marketing strategies.
[Show me the Code]
Starting out with the project, a quick glance at the data will reveal that there are a number of columns that aren’t relevant to the problem statement.
display_all(invoice_df.head(3))
print(f'Shape of the raw DataFrame: {invoice_df.shape}')
| Unnamed: 0 | Amt Rcvd From Custom | Amt Rcvd From Ins Co | Area / Locality | CGST(14%) | CGST(2.5%) | CGST(6%) | CGST(9%) | CITY | Cash /Cashless Type | Claim No. | Cust Type | Customer No. | District | Expiry Date | Gate Pass Date | Gate Pass Time | IGST(12%) | IGST(18%) | IGST(28%) | IGST(5%) | Insurance Company | Invoice Date | Invoice No | Invoice Time | Job Card No | JobCard Date | JobCard Time | KMs Reading | Labour Total | Make | Misc Total | Model | ODN No. | OSL Total | Order Type | Outstanding Amt | Parts Total | Pin code | Plant | Plant Name1 | Policy no. | Print Status | Recovrbl Exp | Regn No | SGST/UGST(14%) | SGST/UGST(2.5%) | SGST/UGST(6%) | SGST/UGST(9%) | Service Advisor Name | TDS amount | Technician Name | Total Amt Wtd Tax. | Total CGST | Total GST | Total IGST | Total SGST/UGST | Total Value | User ID | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0.0 | 0.0 | MAJIWADA | 0.0 | 0.0 | 0.0 | 0.0 | Thane | NaN | NaN | Retail | 67849 | Maharashtra | NaN | NaN | 00:00:00 | 0.0 | 0.0 | 0.0 | 0.0 | NaN | 2015-01-02 | 7005200002 | 11:30:36 | 168303 | 2014-12-13 | 14:29:43 | 49317 | 1203.14 | GENERAL MOTORS | 0.00 | SPARK | 7.005200e+09 | 500.06 | Paid Service | 0.0 | 2348.75 | 400601 | BC01 | THANE | NaN | NO | 0.0 | KA19MA1291 | 0.0 | 0.0 | 0.0 | 0.0 | NaN | 0.0 | RUPESH | 4051.95 | 0.0 | 0.0 | 0.0 | 0.0 | 4051.95 | BC01FS1 |
| 1 | 1 | 0.0 | 0.0 | THNAE | 0.0 | 0.0 | 0.0 | 0.0 | THNAE | NaN | NaN | Retail | 84419 | Maharashtra | NaN | NaN | 00:00:00 | 0.0 | 0.0 | 0.0 | 0.0 | NaN | 2015-01-03 | 7005200003 | 10:07:32 | 173997 | 2015-01-02 | 14:12:18 | 78584 | 804.26 | TATA MOTORS | 197.03 | INDICA | 7.005200e+09 | 0.00 | SMC Value Package | 0.0 | 0.00 | 400603 | BC01 | THANE | NaN | NO | 0.0 | MH43R3046 | 0.0 | 0.0 | 0.0 | 0.0 | NaN | 0.0 | PRASHANT | 1001.29 | 0.0 | 0.0 | 0.0 | 0.0 | 1001.29 | BC01SA2 |
| 2 | 2 | 0.0 | 0.0 | THANE | 0.0 | 0.0 | 0.0 | 0.0 | THANE[W] | NaN | NaN | Retail | 81055 | Maharashtra | NaN | NaN | 00:00:00 | 0.0 | 0.0 | 0.0 | 0.0 | NaN | 2015-01-03 | 7005200004 | 11:12:57 | 173889 | 2015-01-02 | 11:40:44 | 33985 | 180.19 | MARUTI SUZUKI | 0.00 | ZEN | 7.005200e+09 | 0.00 | Running Repairs | 0.0 | 52.95 | 400607 | BC01 | THANE | NaN | NO | 0.0 | AP09AX0582 | 0.0 | 0.0 | 0.0 | 0.0 | NaN | 0.0 | IMRAN | 233.14 | 0.0 | 0.0 | 0.0 | 0.0 | 233.14 | BC01SA2 |
Shape of the raw DataFrame: (492314, 59)
Such columns can be dropped for the time being. We can add them later if needed.
display_all(invoice_cleaned.head(3))
print(f'Shape of the cleaned DataFrame: {invoice_cleaned.shape}')
| CITY | Cust Type | Customer No. | District | Invoice No | Job Card No | KMs Reading | Labour Total | Make | Misc Total | Model | OSL Total | Order Type | Outstanding Amt | Parts Total | Pin code | Regn No | Technician Name | Total Amt Wtd Tax. | User ID | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Thane | Retail | 67849 | Maharashtra | 7005200002 | 168303 | 49317 | 1203.14 | GENERAL MOTORS | 0.00 | SPARK | 500.06 | Paid Service | 0.0 | 2348.75 | 400601 | KA19MA1291 | RUPESH | 4051.95 | BC01FS1 |
| 1 | THNAE | Retail | 84419 | Maharashtra | 7005200003 | 173997 | 78584 | 804.26 | TATA MOTORS | 197.03 | INDICA | 0.00 | SMC Value Package | 0.0 | 0.00 | 400603 | MH43R3046 | PRASHANT | 1001.29 | BC01SA2 |
| 2 | THANE[W] | Retail | 81055 | Maharashtra | 7005200004 | 173889 | 33985 | 180.19 | MARUTI SUZUKI | 0.00 | ZEN | 0.00 | Running Repairs | 0.0 | 52.95 | 400607 | AP09AX0582 | IMRAN | 233.14 | BC01SA2 |
Shape of the cleaned DataFrame: (492314, 20)
In order to start with geolocation based analysis (Problem Statement - 1), the district column is necessary. However it requires cleaning because the values are inconsistent or erroneous at times.
invoice_cleaned.district.nunique()
36
As a result, the district column is re-created using the pincodes provided so as to rectify the errors. pgeocode library is used to extract this information. However, some manual effort is still required to correct the remaining inconsistencies.
invoice_cleaned.district.nunique()
29
Now that these districts have been set, there are a few districts with relatively low frequencies. These districts have been reduced to a single value called others.
other_states = invoice_cleaned.district.value_counts().index[11:]
other_states
Index(['Kerala', 'Delhi', 'Chandigarh', 'Bihar', 'Himachal Pradesh',
'Uttarakhand', 'Odisha', 'Puducherry', 'West Bengal', 'Chhattisgarh',
'Dadra and Nagar Haveli and Daman and Diu', 'Jharkhand', 'Assam', 'Goa',
'Arunachal Pradesh', 'Jammu & Kashmir', 'Lakshadweep', 'Nagaland'],
dtype='object')
invoice_cleaned['district_grp'] = np.where(invoice_cleaned.district.isin(other_states), 'Others', invoice_cleaned.district)
Also, there are 28 unique values for make in the dataset.
invoice_cleaned.make.nunique()
28
These values can be clubbed into a 4 distinct categories:
- Hatchback
- SUV
- Utility
- Luxury
- Sedan
invoice_cleaned['model_type'].value_counts()
Hatchback 281333
SUV 98766
Sedan 95397
Utility 14478
Luxury 2340
Name: model_type, dtype: int64
With this we are ready to approach our first problem statement!
Ownership patterns
The plot above aids us in comprehending our customer base. Before charting, the data was filtered by the cust type column to only include retail customers, as the ownership pattern can only be identified when the consumer owns the automobile.
The majority of our consumers come from the states of Maharashtra and Tamil Nadu. This is most likely attributable to the fact that these states have more service plants. Hatchbacks are the most popular category in the country, followed by SUVs. Maruti Suzuki is the most popular car brand among our consumers. A luxury automobile is owned only by a small percentage of clients.
The above observations suggest that the majority of our customers are from the middle class.
Order types and Service Times
We’ll need some feature engineering before moving on to the next problem statement. The difference (in hours) between the columns JobCardDateTime - signifies the time when the automobile arrived for service, and InvoiceDateTime - shows the time when the invoice was created, is used to create a new column called service time hrs.
This new feature indicates the amount of time, in hours, taken to perform the service.
invoice_cleaned['InvoiceDateTime'] = pd.to_datetime(invoice_df['Invoice Date']+' '+invoice_df['Invoice Time'])
invoice_cleaned['JobCardDateTime'] = pd.to_datetime(invoice_df['JobCard Date']+' '+invoice_df['JobCard Time'])
invoice_cleaned['service_time'] = invoice_cleaned['InvoiceDateTime'] - invoice_cleaned['JobCardDateTime']
invoice_cleaned["service_time_hrs"]=invoice_cleaned["service_time"]/np.timedelta64(1, 'h')
To determine the frequency and average service time, the above figure was created by grouping on the order type column and getting the average and count of the service_time_hrs column. To decrease the impact of outliers, the median was utilised to calculate the average.
After the above-mentioned aggregations, the plot reveals that a substantial percentage of our customer population (about 80%) visits our plant for running repairs and paid services. Running repairs often take roughly 6 hours to complete, whereas paid services typically take a day to complete. Accidental repairs take a long time to complete, which might be correlated to the magnitude of the damage or the availability of parts.
We can probably reduce the service times by knowing the nature of the visit beforehand and stocking up on the parts accordingly.
Let’s analyze whether location plays a role in the time taken to complete a service.
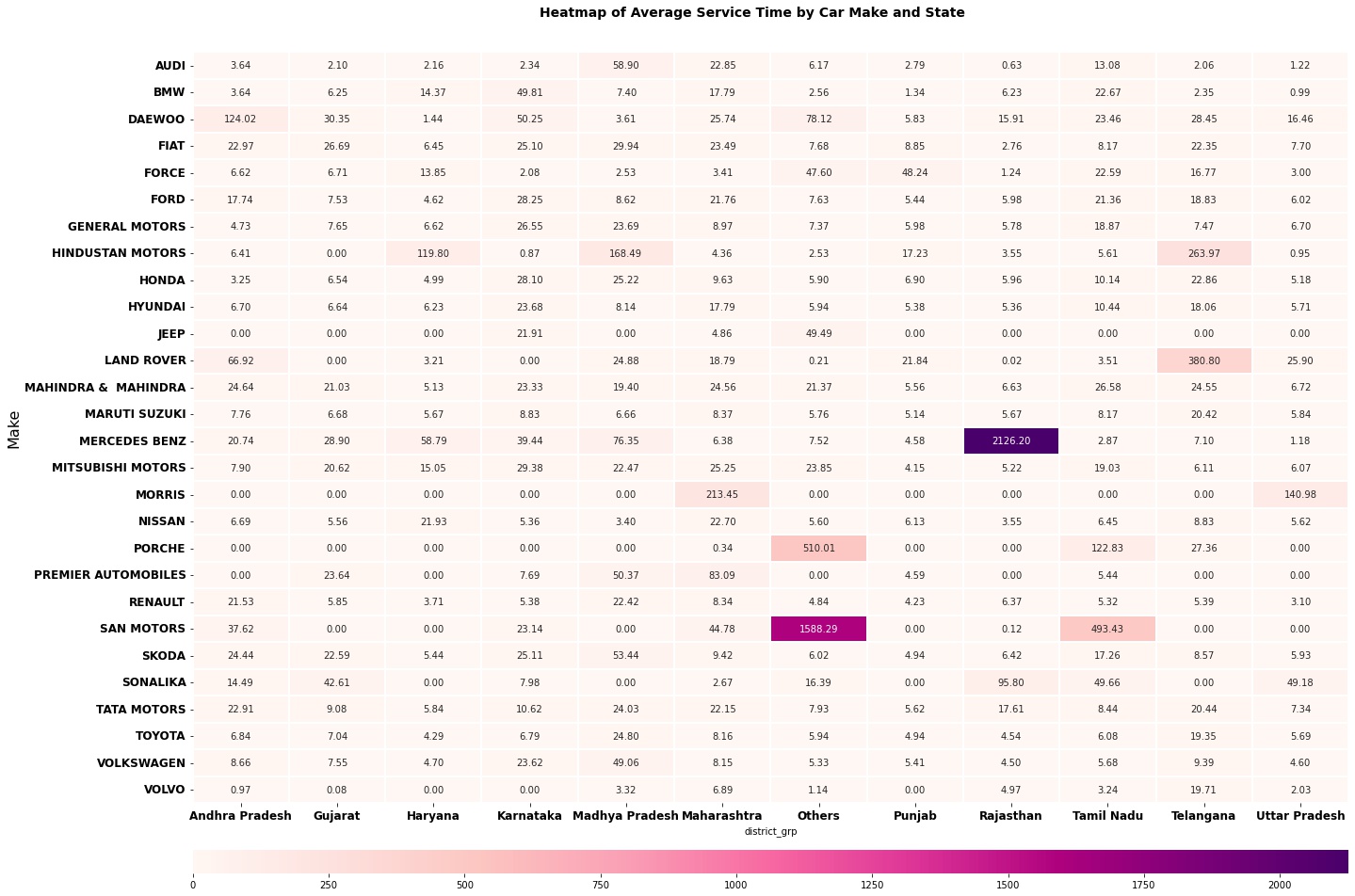
Considering Maruti Suzuki, the most frequent car across states, we observe that the average service time in Telangana is relatively high. The second most popular brand - Mahindra & Mahindra, usually takes a day on average to complete the service.
It would be interesting to check if there is a seasonal trend in the number of incoming customers.
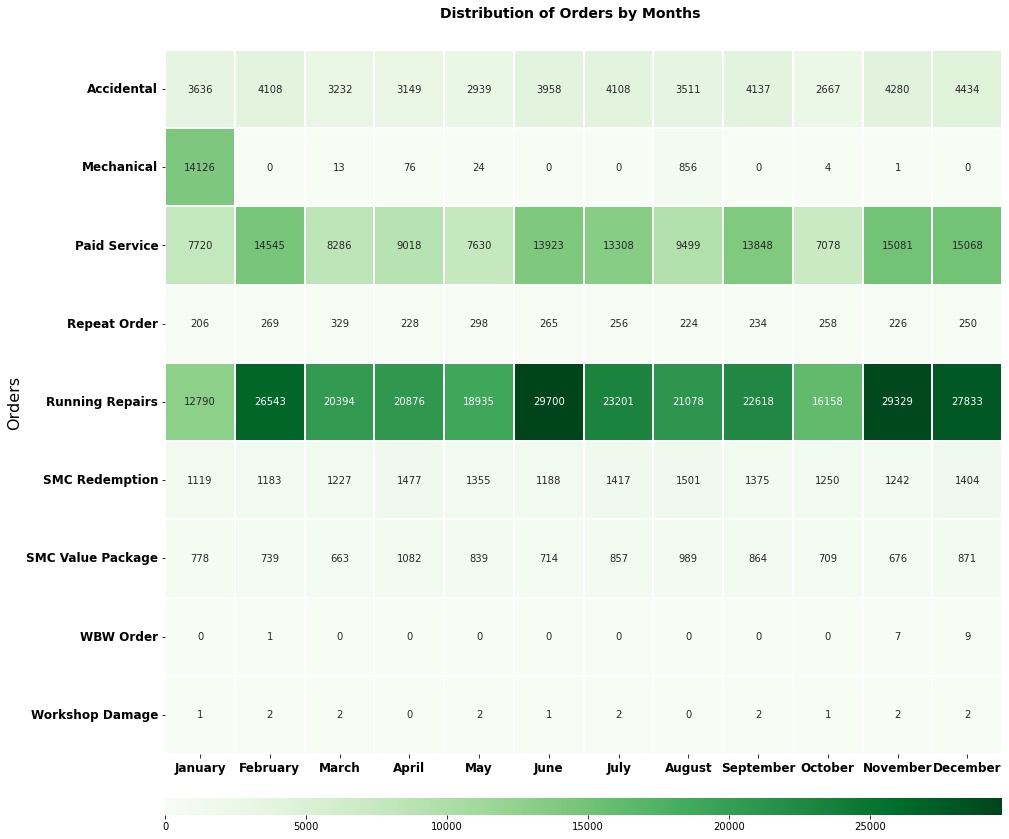
The heatmap above displays the various sorts of orders that have been received over the months. Over the years, we’ve seen that the majority of mechanical orders occur around January and August. Customers visiting a factory for paid service or running repairs, the two most typical forms of orders, do not follow a seasonal pattern.
Since there’s no seasonal trend in the orders received, MFCS can stock up their inventory with common parts like oil and air filters for most popular car brands in order to reduce their service times.
Let’s have a look at the customer arrive times over the dataset at a particular day. These arrival times are calculated based on the JobCardDateTime column.
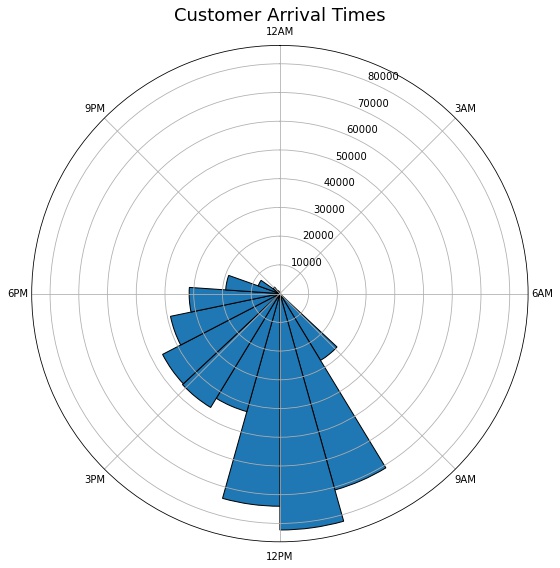
The majority of consumers arrive between 9 a.m. and 12 p.m. After 12 p.m., there is a downward tendency. This may assist MFCS in organising their labour force so that customers receive prompt help during peak hours.
Revenue
Let’s have a look at the revenue generated over the years and it’s respective streams. We will also look at Parts-to-Labour ratio which is the ratio of labor sales to parts sold. The parts-to-labor ratio provides insight into how much a company’s revenue is derived from services performed and how much depends on selling parts. MFCS managers can use parts-to-labor ratio to make informed decisions on how much to charge for labor and parts.
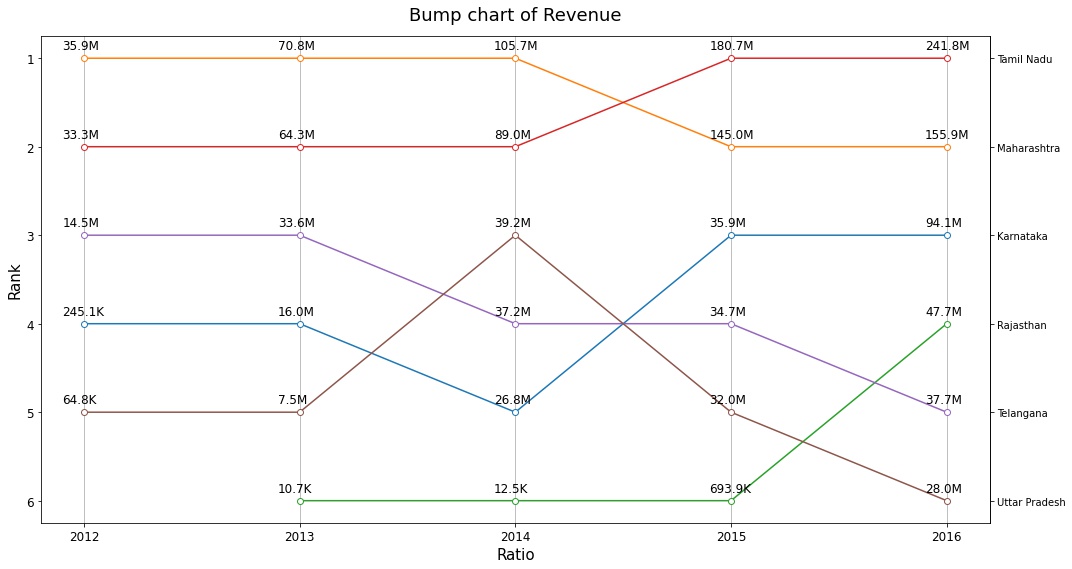
The graph above depicts how revenue has evolved over the years. We only look at the top six states (MH, TN, KA, RJ, TL, UP) because they contribute the most to overall revenue.
Overall, even though Maharashtra lost first place to Tamil Nadu in 2015, the state’s revenue continues to rise. Many rankings shift after 2014, with Uttar Pradesh, which was ranked third in 2014, falling to last place by 2016. Rajasthan’s revenue increased dramatically in 2016, owing to the opening of new factories by MFCS the previous year.
Parts-to-labor ratio is equal to parts sales divided by labor sales. For example, if an auto repair shop sells $80,000 in parts during a certain month and charges customers $100,000 for labor performed during that month, its parts-to-labor ratio for the month is 80,000 divided by 100,000, or 0.8. This means that for every dollar of labor sales that the company makes, it sells 80 cents worth of parts.
According to Bob O’Connor of Motor Magazine, a parts-to-labor ratio in the range of 0.8 to 1 is considered normal for the auto repair industry. If the parts-to-labor ratio exceeds 1, it means parts sales account for a greater proportion of total revenue than labor sales, which indicates that a shop is charging too little for labor or too much for parts.
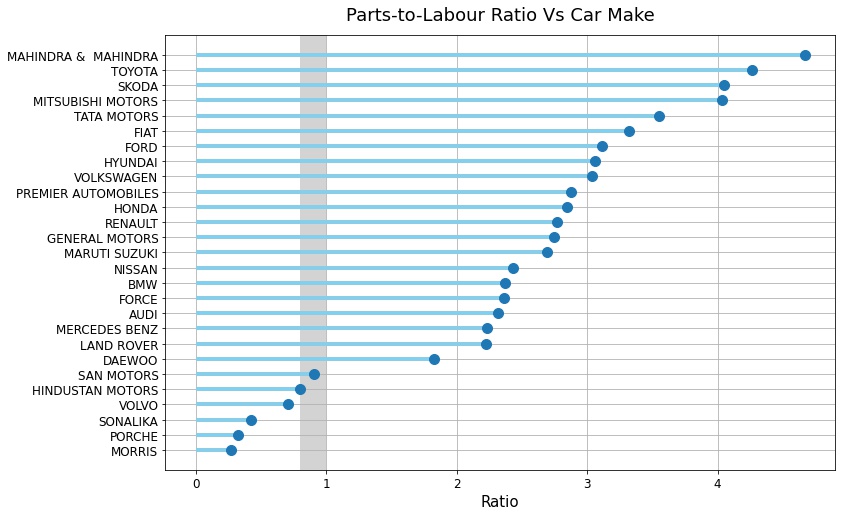
We can see from the diagram above that MFCS is charging too much for parts and too little for labour on majority of the automobiles.
Given that our dataset consists primarily of labor-intensive running repairs and paid services, and that the majority of the automobiles are from the economical group (Maruti Suzuki, Mahindra & Mahindra, and so on), MFCS can strive to balance this ratio in order to maximise their profit margins.
Finally let’s have a look at different sources of customers
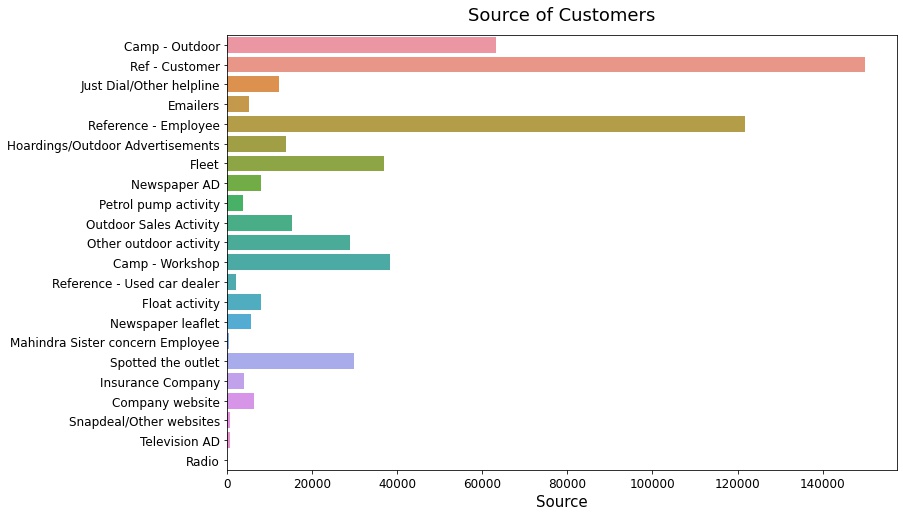
The origin of MFCS’s client population can be seen in this graph. As can be observed, referrals account for about half of the total clients. The remaining 50% of clients come via marketing techniques such as hosting camps/workshops or placing ads in newspapers, television, and other media.
Knowing this, MFCS can improve its profit margins by enhancing its referral policies, lowering advertising expenditures in the process.